PolyMage is a domain-specific language and optimizing code generator for automatic optimization of image processing pipelines, being developed at the Compilers and Programming Systems for High-Performance AI Lab, Indian Institute of Science. PolyMage takes an image processing pipeline expressed by the user in a high-level language (embedded in Python) and generates an optimized parallelized C++ implementation of the pipeline.
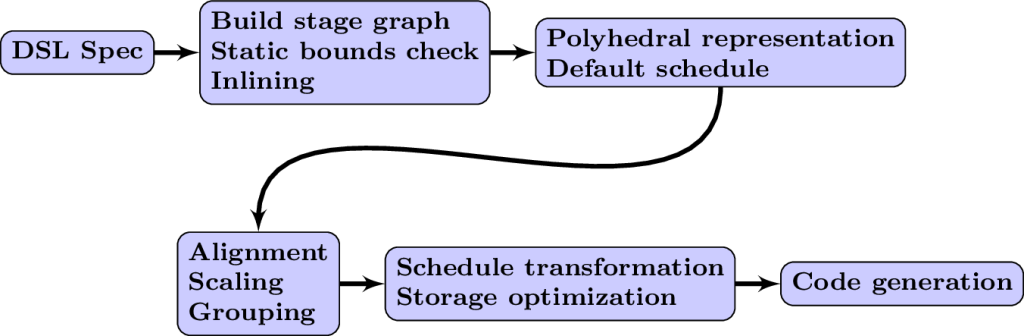
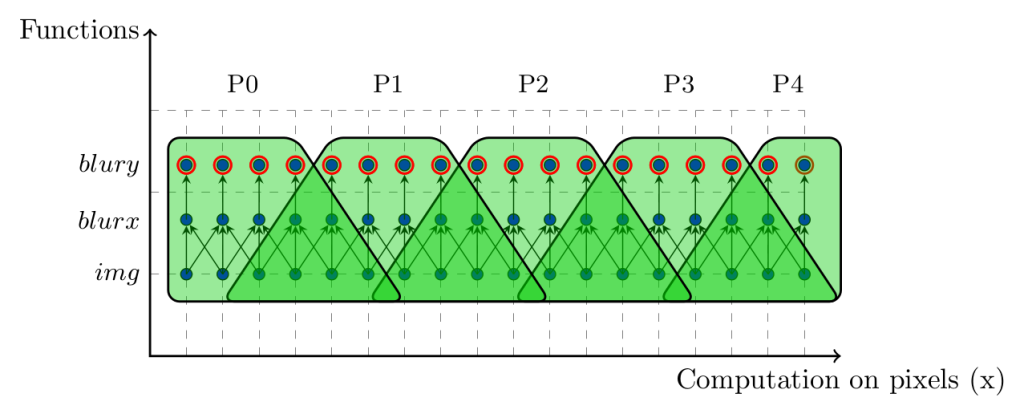
PolyMage’s optimizer primarily relies on the polyhedral framework to automatically perform a sequence of transformations for parallelization and locality optimization on multicore processors. The transformations include ways to enable fusion and tiling across image processing stages, using an asymmetric overlapped tiling technique.
Download
PolyMage is available as free and open source software under the permissive Apache License version 2.0 through its git repository on bitbucket.org here.
PolyMage optimized and base line code for the benchmarks used in its ASPLOS’15 paper can be found in a separate repository here. These generated codes are in the public domain; however, if you plan to reuse these, please consider including a note stating that these were generated by PolyMage, and cite the polymage-benchmarks github repo or this web page. Do keep in mind that the optimization capabilities of PolyMage’s compiler/code generator have changed significantly since its release right after ASPLOS 2015.
PolyMage generated code typically performs best when compiled with Intel’s C/C++ compilers.
Examples
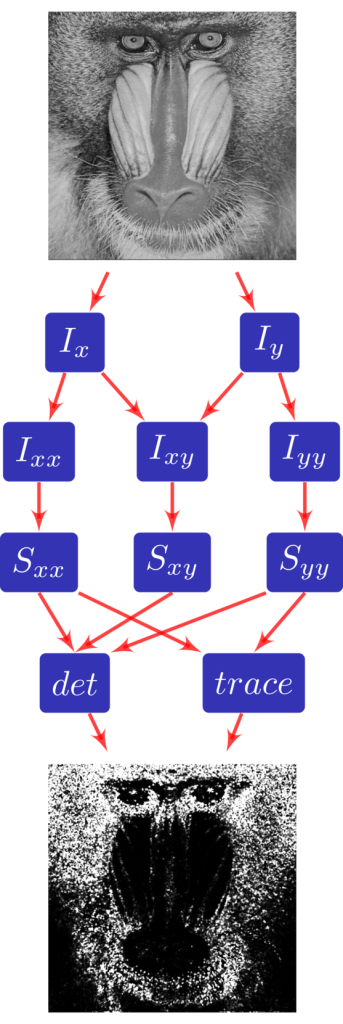
Harris Corner Detection
R, C = Parameter(Int, "R"), Parameter(Int, "C")
I = Image(Float, "I", [R+2, C+2])
x, y = Variable("x"), Variable("y")
row, col = Interval(0, R+1, 1), Interval(0, C+1, 1)
c = Condition(x, '>=', 1) & Condition(x, '<=', R) & \
Condition(y, '>=', 1) & Condition(y, '<=', C)
cb = Condition(x, '>=', 2) & Condition(x, '<=', R-1) & \
Condition(y, '>=', 2) & Condition(y, '<=', C-1)
Iy = Function(varDom = ([x, y], [row, col]), Float, "Iy")
Iy.defn = [ Case(c, Stencil(I(x, y), 1.0/12, \
[[-1,-2,-1], \
[ 0, 0, 0], \
[ 1, 2, 1]])) ]
Ix = Function(varDom = ([x, y], [row, col]), Float, "Ix")
Ix.defn = [ Case(c, Stencil(I(x, y), 1.0/12, \
[[-1, 0, 1], \
[-2, 0, 2], \
[-1, 0, 1]])) ]
Ixx = Function(varDom = ([x, y], [row, col]), Float, "Ixx")
Ixx.defn = [ Case(c, Ix(x, y) * Ix(x, y)) ]
Iyy = Function(varDom = ([x, y], [row, col]), Float, "Iyy")
Iyy.defn = [ Case(c, Iy(x, y) * Iy(x, y)) ]
Ixy = Function(varDom = ([x, y], [row, col]), Float, "Ixy")
Ixy.defn = [ Case(c, Ix(x, y) * Iy(x, y)) ]
Sxx = Function(varDom = ([x, y], [row, col]), Float, "Sxx")
Syy = Function(varDom = ([x, y], [row, col]), Float, "Syy")
Sxy = Function(varDom = ([x, y], [row, col]), Float, "Sxy")
for pair in [(Sxx, Ixx), (Syy, Iyy), (Sxy, Ixy)]:
pair[0].defn = [ Case(cb, Stencil(pair[1], 1, \
[[1, 1, 1], \
[1, 1, 1], \
[1, 1, 1]])) ]
Det = Function(varDom = ([x, y], [row, col]), Float, "det")
d = Sxx(x, y) * Syy(x, y) - Sxy(x, y) * Sxy(x, y)
Det.defn = [ Case(cb, d) ]
Trace = Function(varDom = ([x, y], [row, col]), Float, "trace")
Trace.defn = [ Case(cb, Sxx(x, y) + Syy(x, y)) ]
Harris = Function(varDom = ([x, y], [row, col]), Float, "harris")
coarsity = Det(x, y) - 0.04 * Trace(x, y) * Trace(x, y)
Harris.defn = [ Case(cb, coarsity) ]
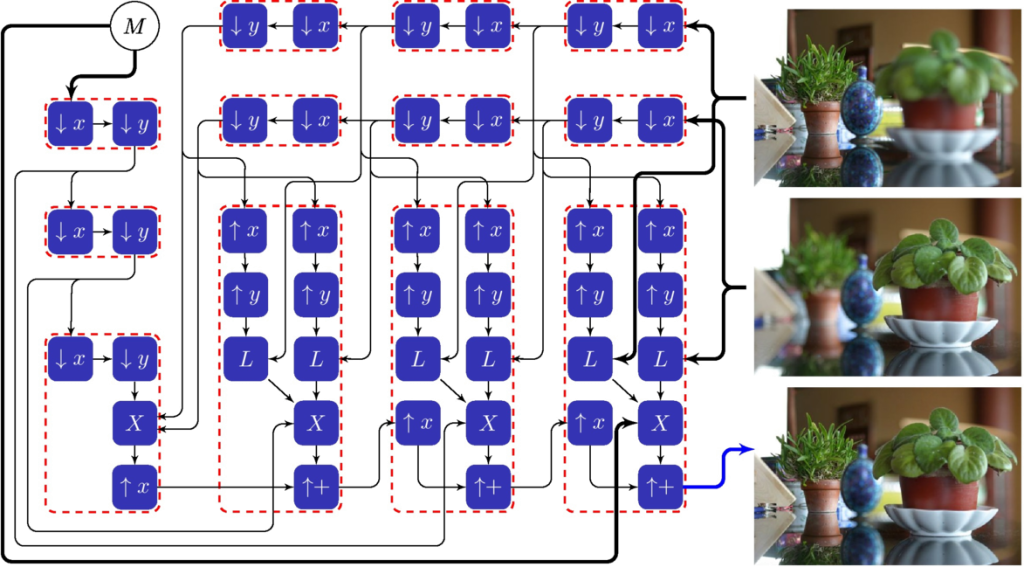
Pyramid Blending
Performance
| Benchmark | Stages | Image size | PolyMage (1 core) | PolyMage (16 cores) | OpenCV |
|---|---|---|---|---|---|
| Harris Corner Dectetion | 11 | 6400 * 6400 | 233.79 ms | 18.69 ms | 810.24 ms |
| Pyramid Blending | 44 | 3 * 2048 * 2048 | 196.99 ms | 21.91 ms | 197.28 ms |
| Unsharp Mask | 4 | 3 * 2048 * 2048 | 165.40 ms | 14.85 ms | 349.57 ms |
| Local Laplacian | 99 | 3 * 2560 * 1536 | 274.40 ms | 32.35 ms | * |
| Camera Pipeline | 32 | 2528 * 1920 | 67.87 ms | 5.86 ms | * |
| Bilateral Grid | 7 | 2560 * 1536 | 89.76 ms | 8.47 ms | * |
| Multiscale Interpolation | 49 | 3 * 2560 * 1536 | 101.70 ms | 18.18 ms | * |
Machine configuration: Dual socket 8-core Xeon E5 2680 (SandyBridge) 2.70 GHz processors with 64 GB of non-ECC RAM running Linux 3.8.0-38 (64-bit)
Compiler: Intel C/C++ compiler 14.0.1 with flags “-O3 -xhost”
PolyMage (unoptimized) is code generated with only scalar optimizations enabled.
PolyMage (optimized) is auto-tuned code generated with grouping, tiling, storage optimization and vectorization enabled.
Halide (tuned) schedules for Local Laplacian Filters, Camera Pipeline, Bilateral Grid, and Multiscale Interpolation are optimized schedules available with the Halide distribution, and were further tuned for our target machine.
Harris Corner Detection
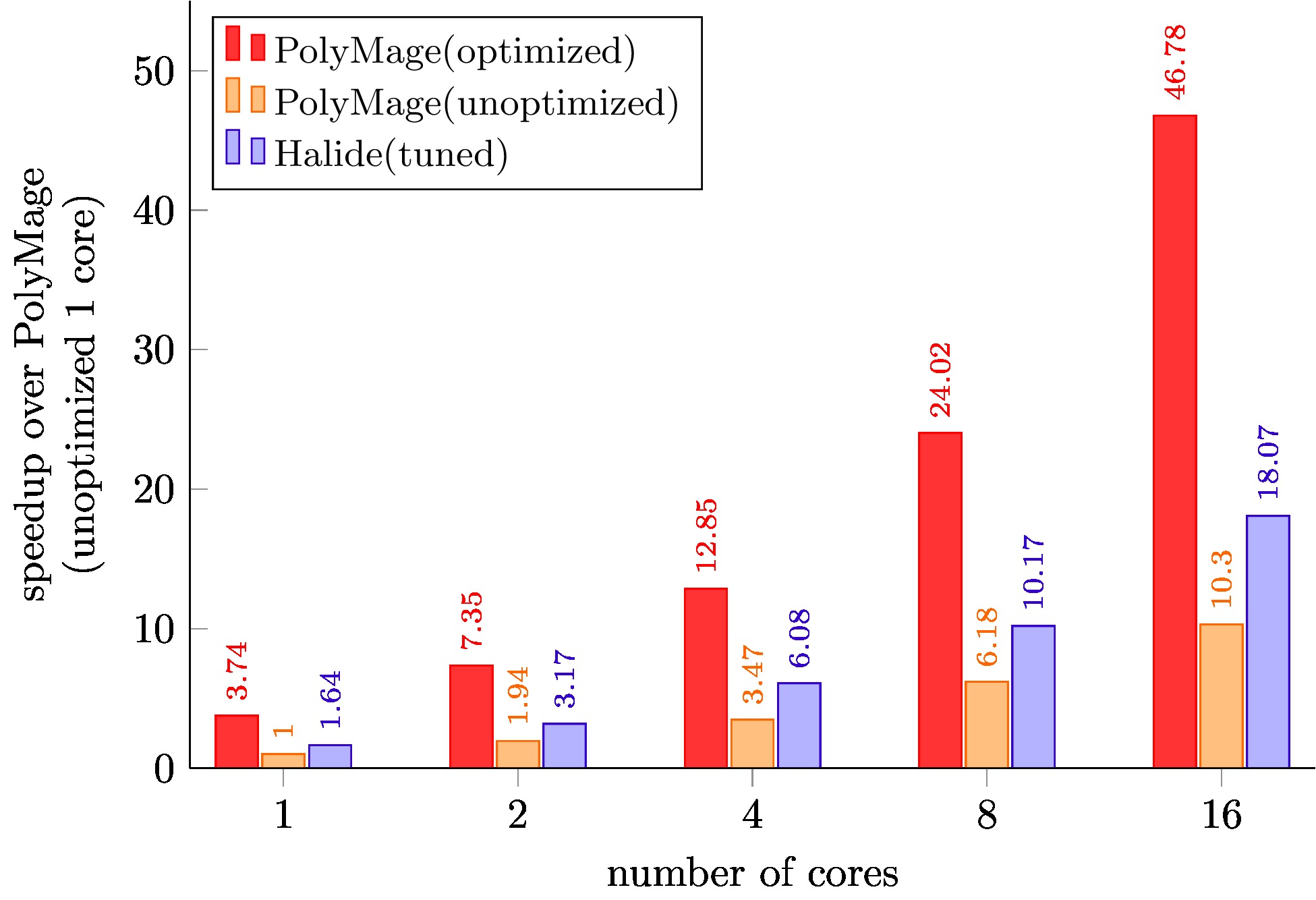
Multiscale Interpolation
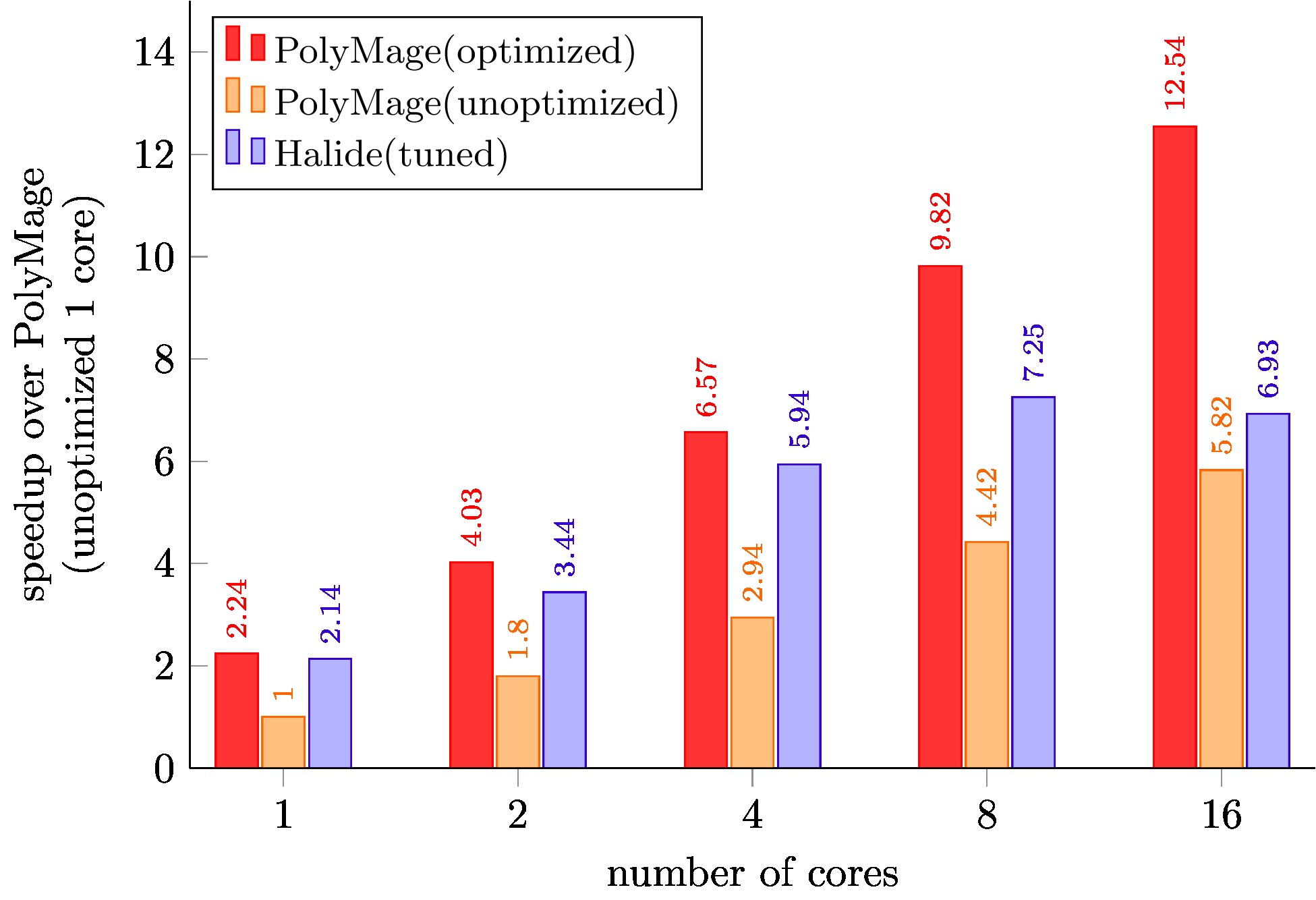
Bilateral Grid
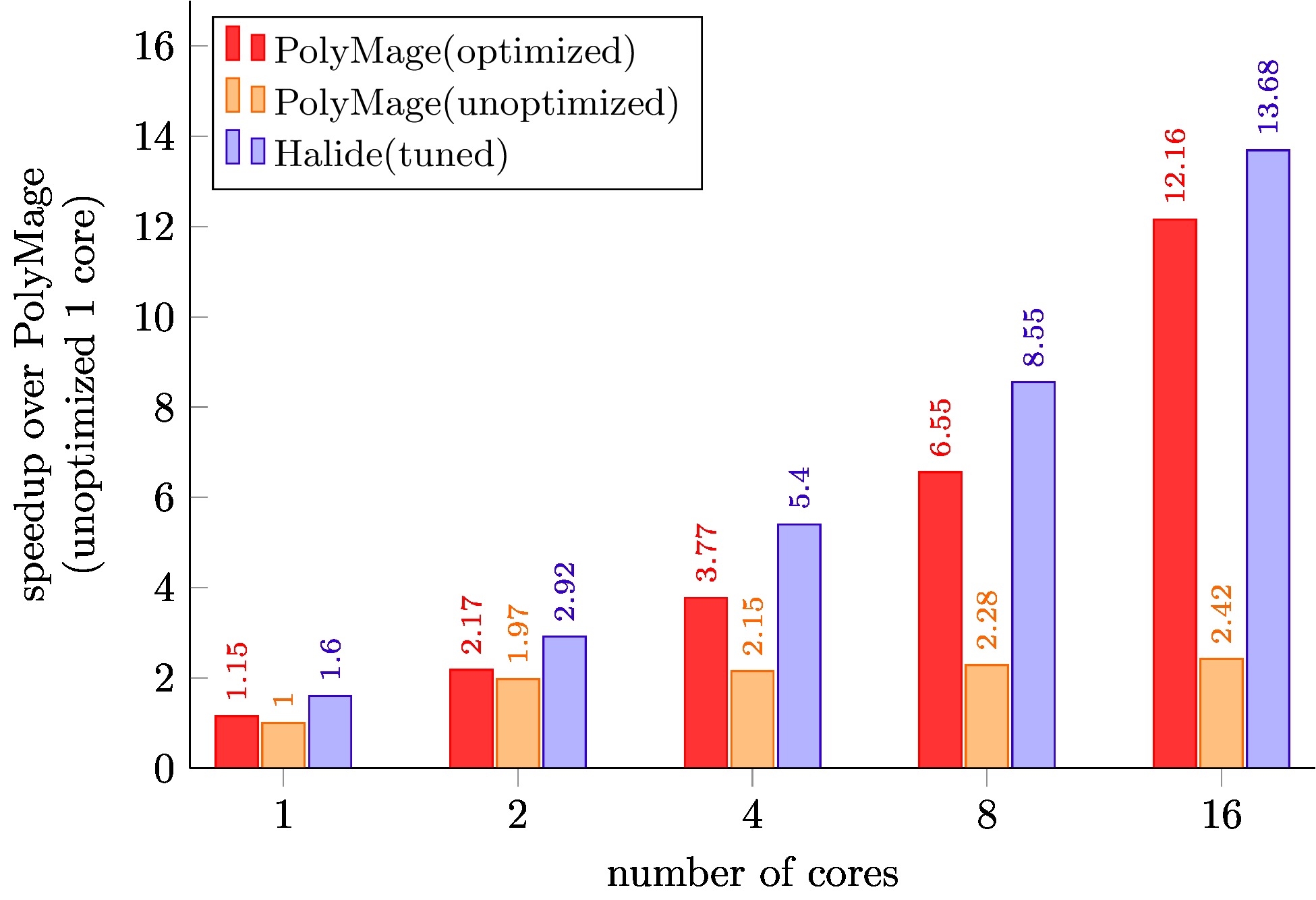
Pyramid Blending
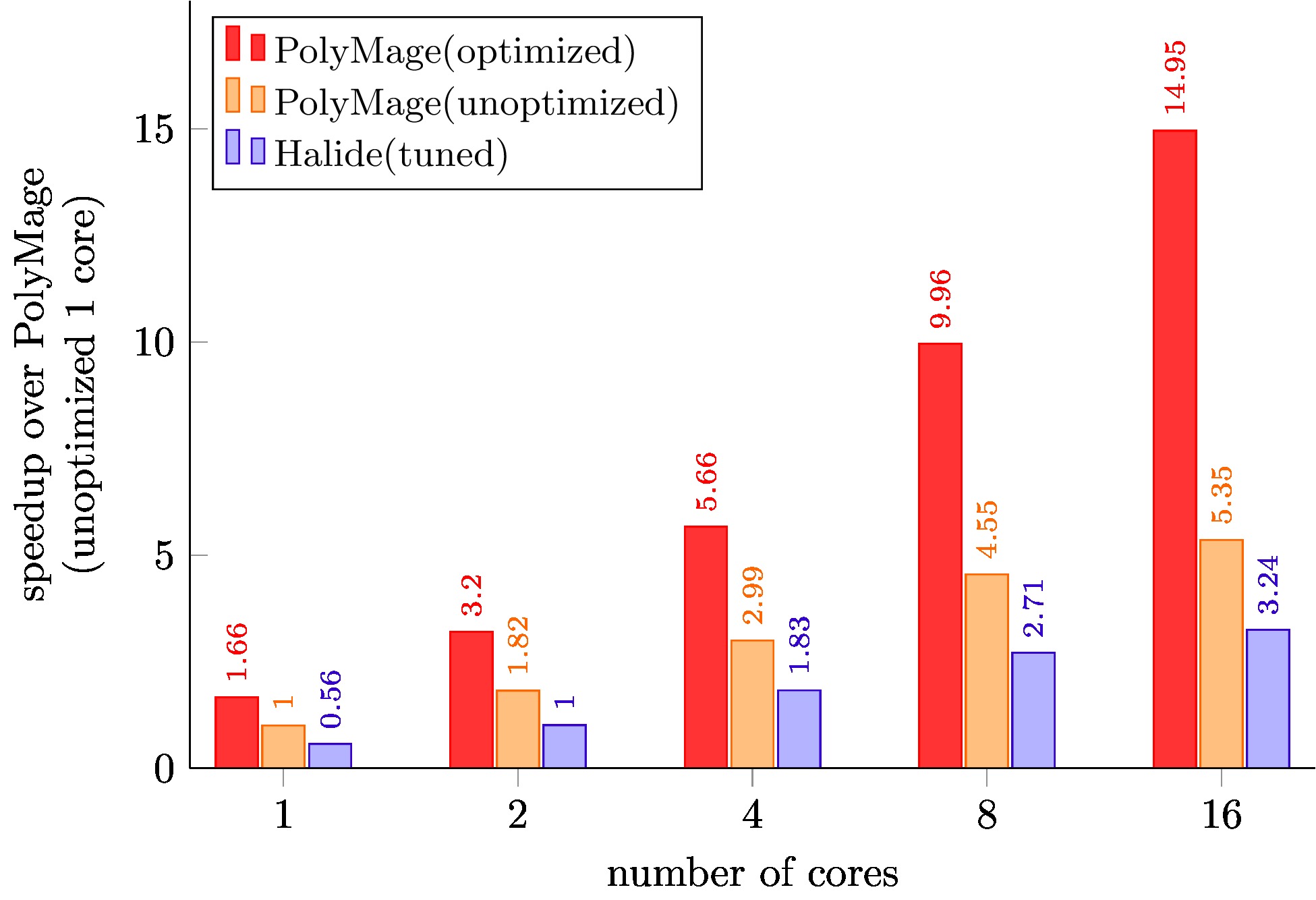
Local Laplacian Filters
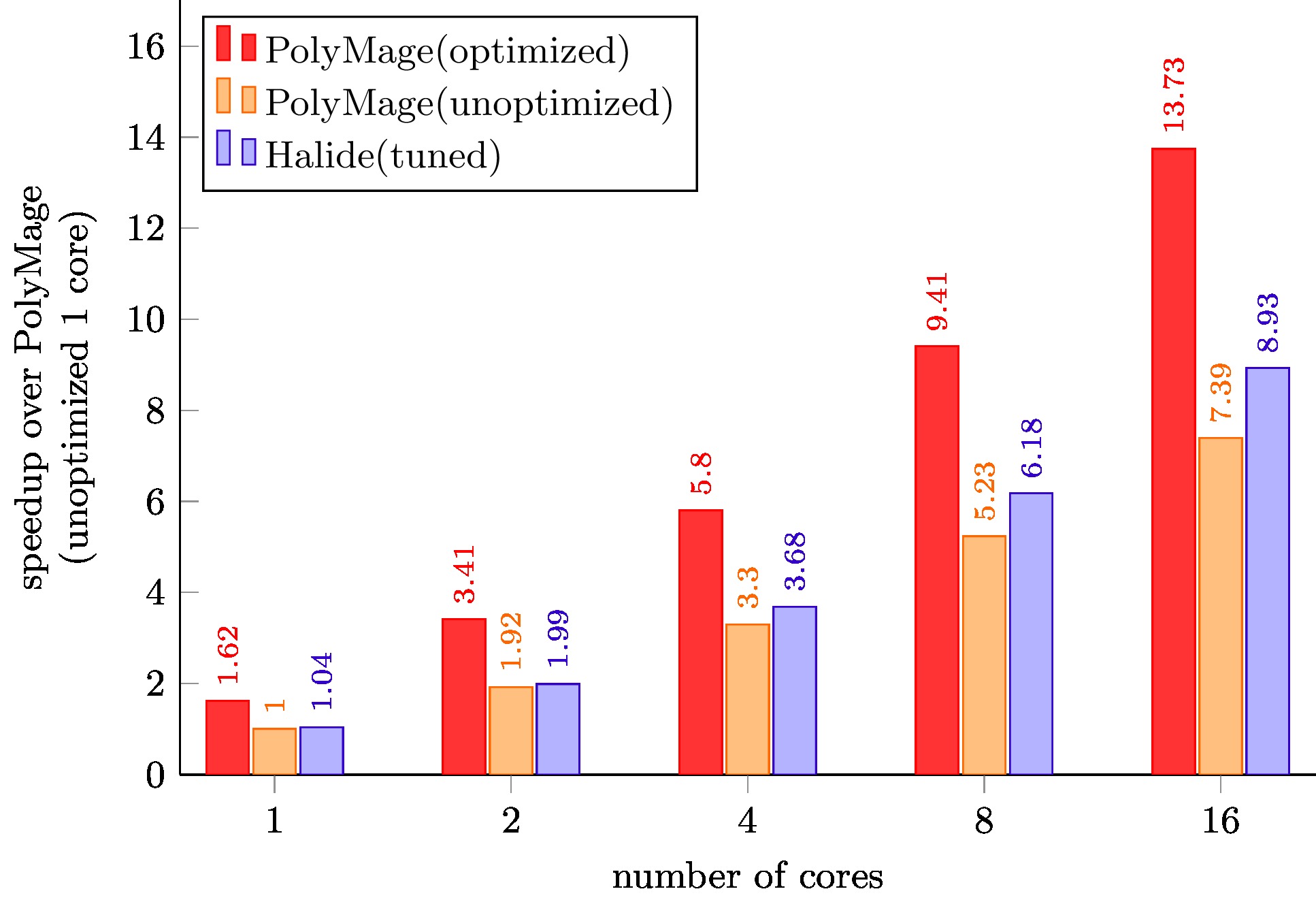
Camera Pipeline
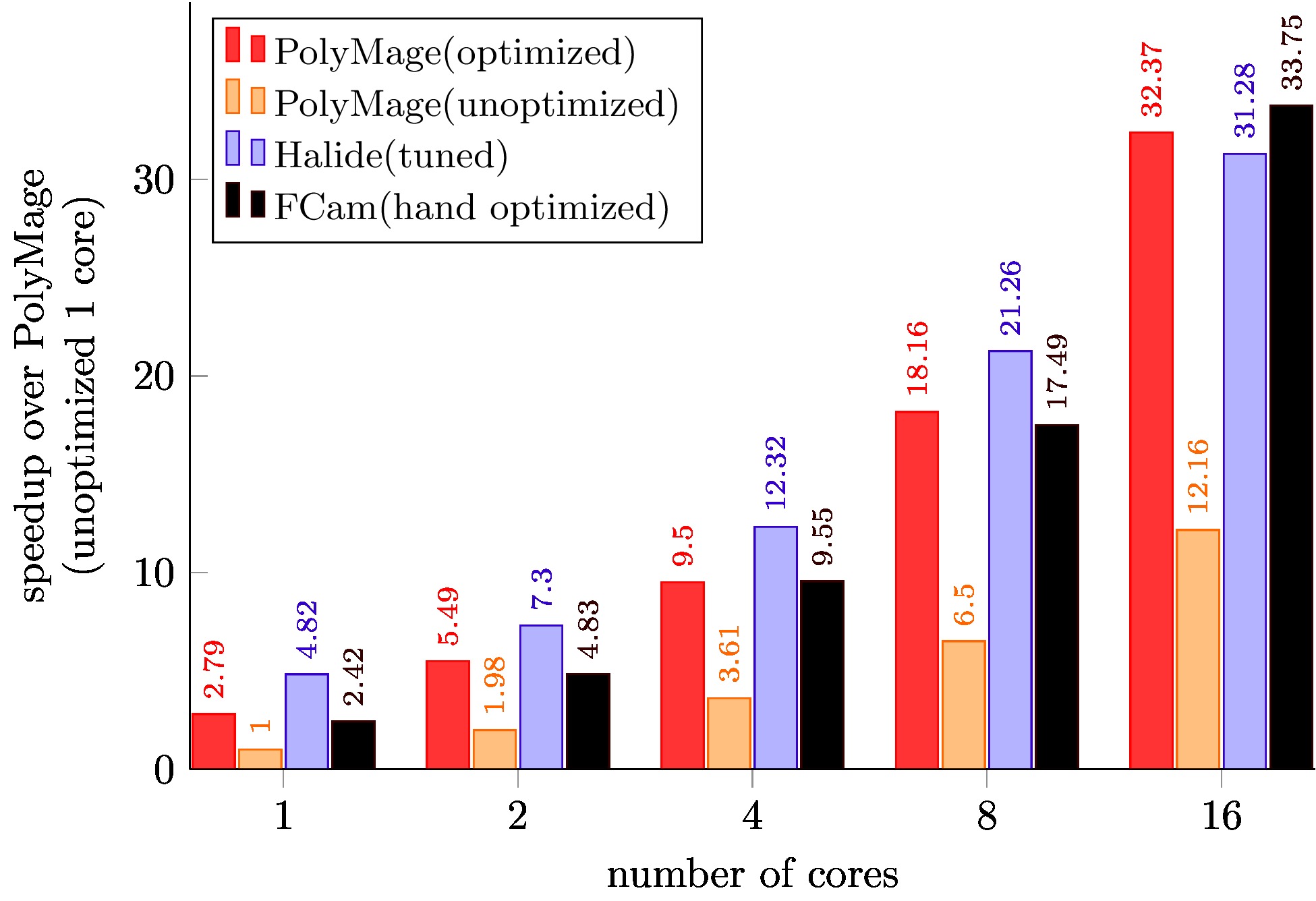
Publications
- PolyMage: Automatic Optimization for Image Processing Pipelines (PDF, slides)
Ravi Teja Mullapudi, Vinay Vasista, Uday Bondhugula
20th International Conference on Architectural Support for Programming Languages and Operating Systems (ASPLOS 2015), Mar 2015. - An Effective Fusion and Tile Size Model for Optimizing Image Processing Pipelines
Abhinav Jangda, Uday Bondhugula
ACM SIGPLAN symposium on Principles and Practice of Parallel Programming (PPoPP), Feb 2018 (to appear).
Artifact evaluated (reusable and available).
